观看笔记:《我如何使用LLM》-- Andrej Karpathy
Posted on Mon 10 March 2025 in Computer Science
目前生态 Current Ecosystem
- 大型科技公司:ChatGPT, Gemini (Google), Meta AI, Copilot (Github / Microsoft)
- 初创公司: Claude (Anthropic), Grok (xAI / Twitter), Perplexity, DeepSeek, Le Chat (Mistral)
一些评分榜单
3:05 - 4:03 主要是演示一下ChatGPT功能
基础概念 Basic Concepts: Tokens and Training
TikTokenizer 直观地展示了输入的文字是如何被转换成Token的。我们输入模型的其实是一串 Token,模型返回给我们一串Token,并最终被前端界面加工成文字展示出来。本质上,我们和大语言模型的对话事实上是持续的构建一串一维的Token序列。通常,大语言模型都预先定义了一个固定大小的上下文窗口(Context Window)。这实质上就是大预言模型对话的本质,即上述的一维序列被持续的添加进上下文窗口中,并在后续的对话中用户和助手轮流进行输入。若借用计算机的一个常用知识来解释的话,我们可以将上下文窗口视作此大语言模型的工作内存。
大预言模型的训练从高维度看可以分为两部:预训练(pre-training)和后训练(post-training)。 预训练将从互联网上采集到的超大量语料进行压缩,并生成一个大脑的“Zip文件”(🙂)。当然,它实质上是一种概率性的的压缩,我们并不能解压这个“Zip文件”,也无法实质的从压缩文件中提取任何信息,因为整个互联网上的信息实在是太多了。这个“Zip文件”所代表的神经网络只是通过学习输入的信息来进行回答:基于我当前学习到的参数,给定当前的上下文窗口,下一个Token会是什么。抽象地说,通过这样的学习,模型能够学习到语料里面所携带的知识,这便是我们通常所说的大模型的能力涌现(Wei et al., 2022)。如果我们需要模型能学习到更多东西,能记录的上下文越多,那么模型所携带的参数越多,所需要的语料库就越大。一些惊人的统计数据表明,这一步骤可能要花费$10M+,三个月时间,1000+ GPU。通常我们可以看到,模型都会标识其训练数据截止日期,且通常都在几个月之前。 后训练则是基于预训练的模型进行“微调”。因为我们并不是想要模型输出训练数据中的内容,而是为其注入一个灵魂。如ChatGPT就是基于某个版本的GPT模型进行微调,让他能够以AI助手的身份,礼貌和安全地与用户进行对话。同理,其他的开发者也可以基于某个预训练模型进行微调,使其增加某些方面的知识或者在特定的任务中表现更好。后训练的方法主要包括SFT,RLHF,基于对话的强化学习等。
13:27 - 18:00 几个基础的问答
18:00 - 22:54 不同的模型,不同的价格,也带来了不同的表现,基于你自己的判断(钱包深度)进行选择。
思维链模型 Thinking Models
在当前最新的模型中,思维链的技术被广泛应用。通过后训练的强化学习(Reinforcement Learning),模型需要练习一些已经定义的问题。一个生动的类比就是一个学生学数学的时候做一些习题集之后,再根标准答案进行对比 -- 这样学生就能知道一个标准的回答,并在之后遇到类似的题目中能够复用其中的方法。使用这种方法的原因,首先当然是模拟人类学习的过程,其次是因为解决问题的思考过程太过复杂和多变,对于人类标注员来说难以进行描述,还不如让模型从实际的题目和答案中进行学习。在这个过程中,模型能够优化自己的思考模式。这也是过去一年业界的主要研究方向。在新型的模型中,这种思考过程被记录在上下文窗口中(🤔️💭)。比如,DeepSeek就能显示记录自己的思考过程(DeepSeek-AI, 2025)。
25:33 - 31:02 解决代码问题的例子:无思维链 v.s 有思维链;在各种AI应用中,通常会有这个选项,你可以根据应用场景进行选择。
使用工具 Using Tools
人类会使用工具,模型也应该能够使用。让模型使用工具的方法有很多。业界使用的方法通常是让模型自主决定。最先被引入模型的工具是搜索引擎。我们以此为例来讲解。当模型返回某种特殊的Token,就代表模型想要使用网络搜索,应用层的代码将会使用模型生成的查询进行搜索,并将结果返回进上下文里 -- 这个过程对于用户是不可见的。使用搜索引擎能够相当程度的提升模型的准确率,尤其是在一些较为近期的问题上,模型可能没有此训练数据,但是能够通过搜索引擎的结果做出更准确的判断。有时AI应用可以自己决定,有时需要指定使用搜索工具才能激活。
39:17 - 41:50 Perplexity 的 搜索功能演示
深度研究(Deep Research)是一项非常有用的进阶功能。模型会结合思维链与搜索引擎,进行长达数分钟的思考,并给出一份详细的研究报告。当然,详细并不代表它永远是正确的。Karpathy展示了一个关于美国AI研究室的例子,其中AI错误的列举了Hugging Face和 ElutherAI的数据(二者都不是来自美国),且数据也不一定完全准确。
相较于互联网搜索,文件上传能够更准确提供有用的知识。在阅读一些你不熟悉的领域或者语言的时候,可以使用AI帮助你总结和解答疑问。
代码解释器也是一项非常有用的功能。ChatGPT能够调用Python来执行思考中的代码,这样就能够进行一些更为复杂的运算。此项功能通过习题集的方式让GPT模型进行学习,进而能能够自行决定在哪个时候使用代码解释器来进行运算。但是这个功能不是每个AI应用都有。
1:04:40 - 1:09:00 用ChatGPT做数据分析。
1:09:10 - 1:14:03 Claude 能够生成一些 Artifact,并在单独的窗口打开。这包括一些Markdown文档,代码片段,HTML网页,和单个的React应用。 Claude生成的知识问答闪卡的例子和制作概念流程图的例子。
虽然ChatGPT和Claude都或多或少能使用代码作为工具,但是复制粘贴来回对话实在是太麻烦了。相比较之下,Cursor能够与本地代码文件进行交互,这对于开发者来说更加方便和有用。Cursor使用Claude的API来作为推理引擎。在Cursor Composer的交互中,用户只要输入自然语言的指令,Cursor就会生成对应的代码命令并执行。Karpathy 展示了一个用Cursor开发的经典游戏 tic-tac-toe 的网页实现的例子。在这个例子中,他只用了数行自然语言的命令,让Cursor生成新的React项目,清理模版代码,并开发应用。Karpathy称之为Vibe Coding:你给AI一些指令,然后翘着二郎腿等就行了。
模态 Modality
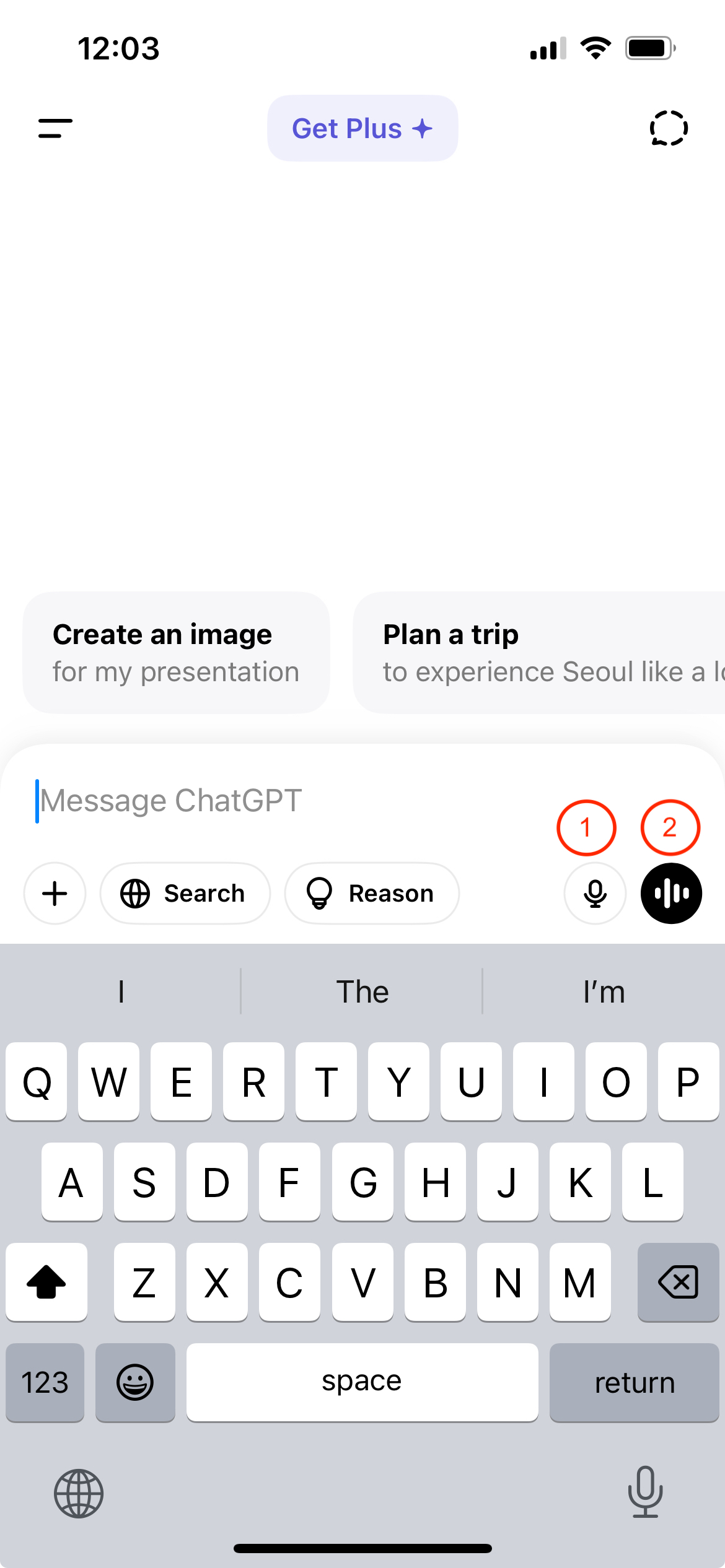
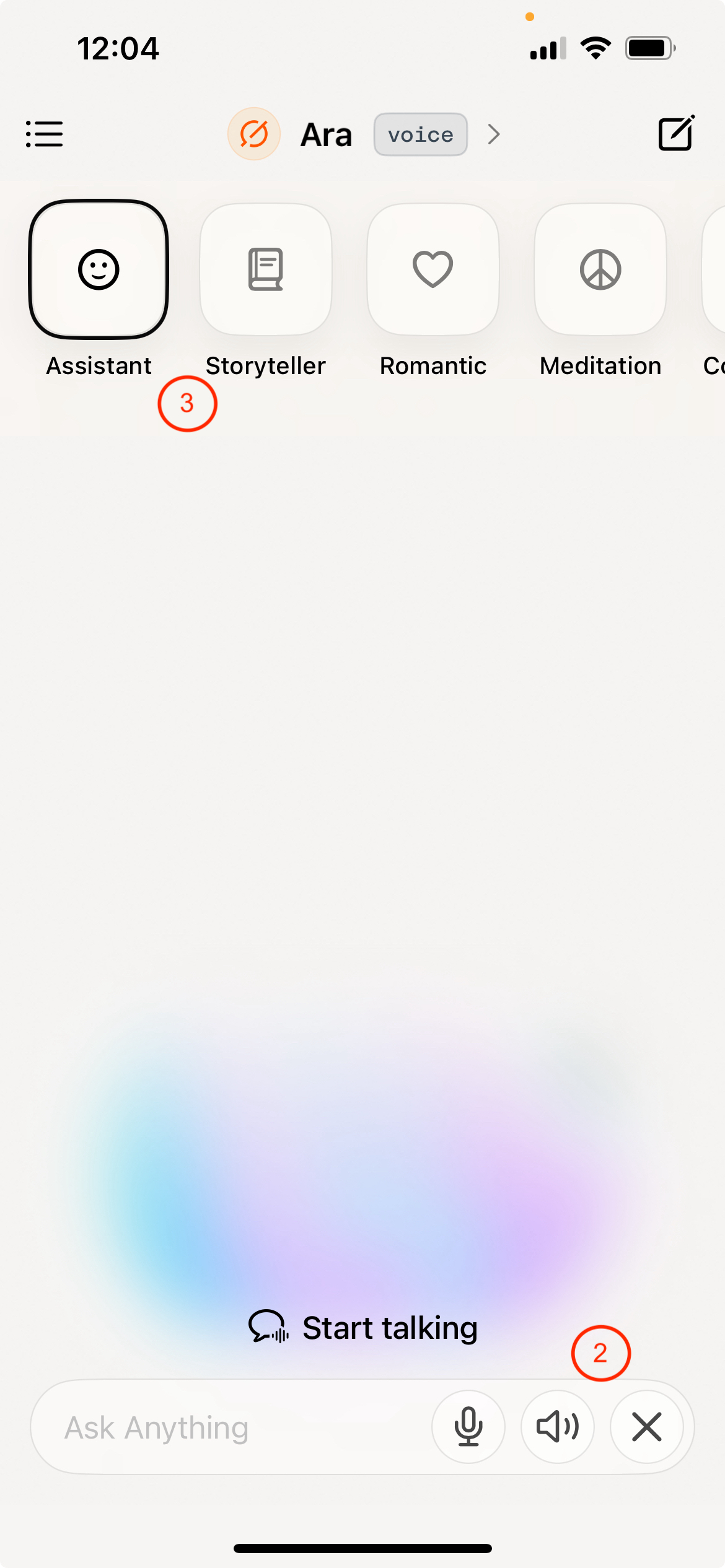
语言模型的初衷是通过文字来进行交互,但是人类的自然交互中,还有语音,图像,甚至视频等多种形式 -- 我们称之为模态(Modality)。因此,对于大语言模型来说,能够进行多模态的交互(输入和输出)。在手机上,我们可以用系统语音识别文字功能。语音识别在特定的名称上可能识别不准确,某些时候我们还是要打字的方式输入。上述这些输入方式通常都是使用外置的文字和语音转换系统。如果大预言模型本身也有能够直接接受语音和视频的模式,那么整个通讯的链路会更加流畅。对于大语言模型来说,也可以使用将文字加工成Token的概念,将音频加工成Token来训练模型进行输入和输出。接着,Karpathy展示了更多让ChatGPT说话的例子,比如用Yoda和海盗的声音说话。但是,可能是由于语料的原因,在语音模式下,AI会有更高的几率拒绝回答。上面的截图中展示了 ChatGPT 的(1)语音输入和(2)语音模式,以及Grok的(2)语音模式和(3)语音模式下的对话个性选项。
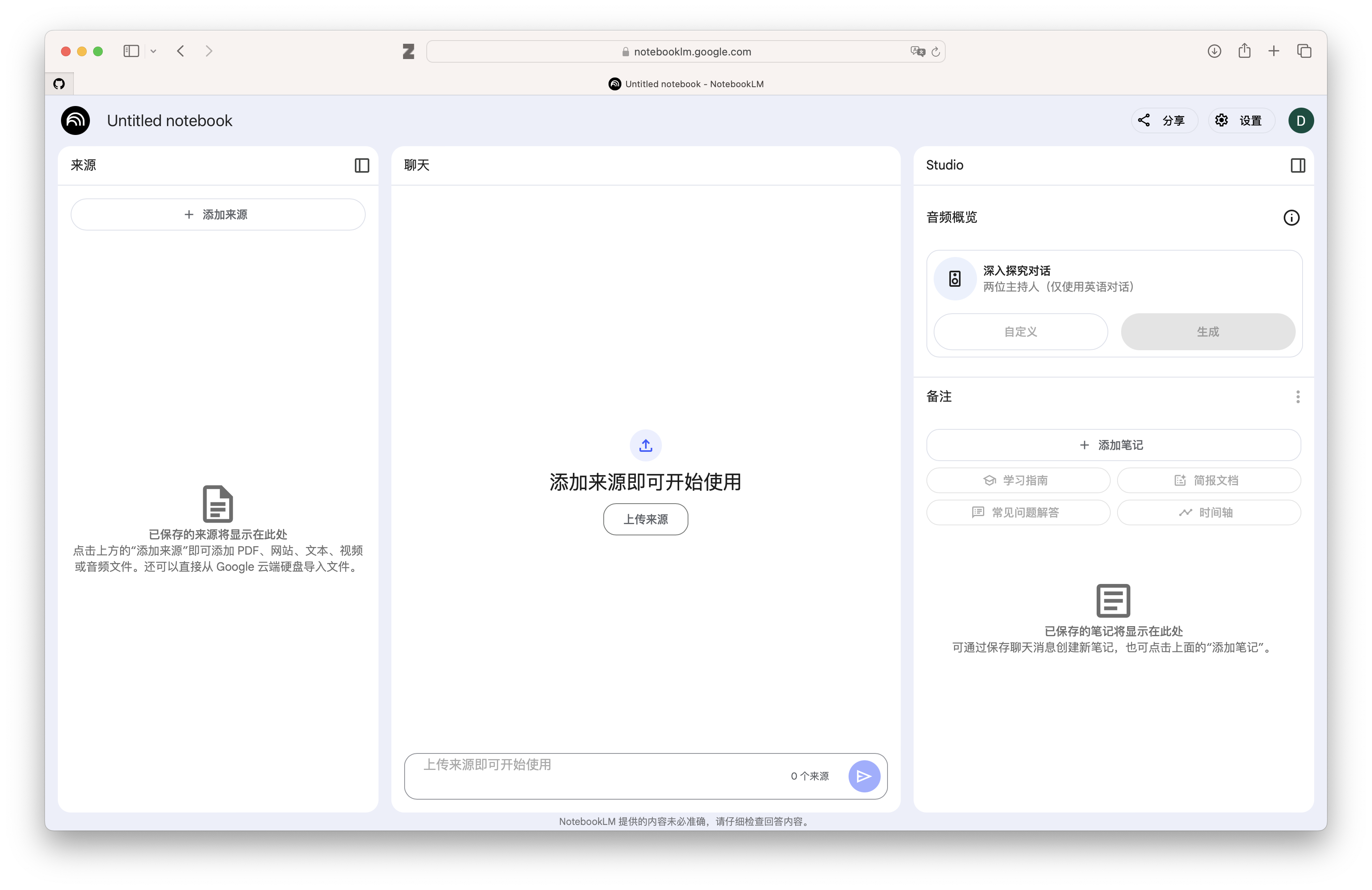
除了传统的对话框模式,也有其他的交互模式。比如Google的NotebookLM。整个UI框架分为三部分:左边是用户添加的资料库,中间是大语言模型的对话窗口,而最右边又进一步分为音频概览和笔记。音频概览可以生成一个Podcast讨论来对于上传的文本进行概述,且用户可以给予特定的指示生成不同类型的Podcast讨论;此外,还有一个交互模式,用户可以参与进来,随时打断Podcast并提问。笔记则可以分为用户自己生成的笔记和自动生成的笔记。
图片也是模态的一种。我们可以以同样的方式将图片Token化,将其切分成小块,使得模型可以输入和输出图片。对于大语言模型来说,模型本身甚至不需要知道输入的Token是文字,图片,还是声音,它就能学习其中的统计分布,并生成(预测)接下来的Token。掌管输入和输出的编码器(Encoder)和解码器(Decoder)则负责将多模态的输出和输出进行转换。Karpathy分享了食品营养成分表,体检报告分析,数学公式转化Latex等应用场景的例子。此外,AI也可以生成图片,如 OpenAI 的DALL-E,还有Ideogram。
1:49:21 - 1:52:25 大语言模型也能够看视频。可以通过摄像头Feed和语音跟大预言模型对话,识别生活中的物件等。
💄AI Video Model Comparison: Text to Video
— Heather Cooper (@HBCoop_) March 3, 2025
10 Models included:
• Google Veo2
• Adobe Firefly Video
• Hunyuan Video
• Pika 2.1
• Wan-2.1
• Runway Gen-3
• Kling AI 1.6
• Luma Ray2
• Hailuo MiniMax
• Sora (not on grid, but in the full video)
I used the same prompt on… pic.twitter.com/D3i7yHokXV
1:52:43 - 1:53:28 Cooper在推特上发布的视频生成模型的对比。
附加功能 Additional Features
除了不同的模态生成以外,AI工具们也提供了附加功能。还是以ChatGPT为例子,持久记忆(Memory)功能能保存某项对话中的知识点,并附加给后续的新对话中。这项功能是自动开启的,也可以手动触发。本质上,此类型的功能将某些对话内容记录到与用户关联的数据库中,并在后续用户开启新对话时将相关的数据放到上下文窗口里来,这样模型就能直接进行回答,也可以表现为针对各个用户的定制化回答。
1:54:30 - 1:56:45 指定ChatGPT保存了一个记忆。
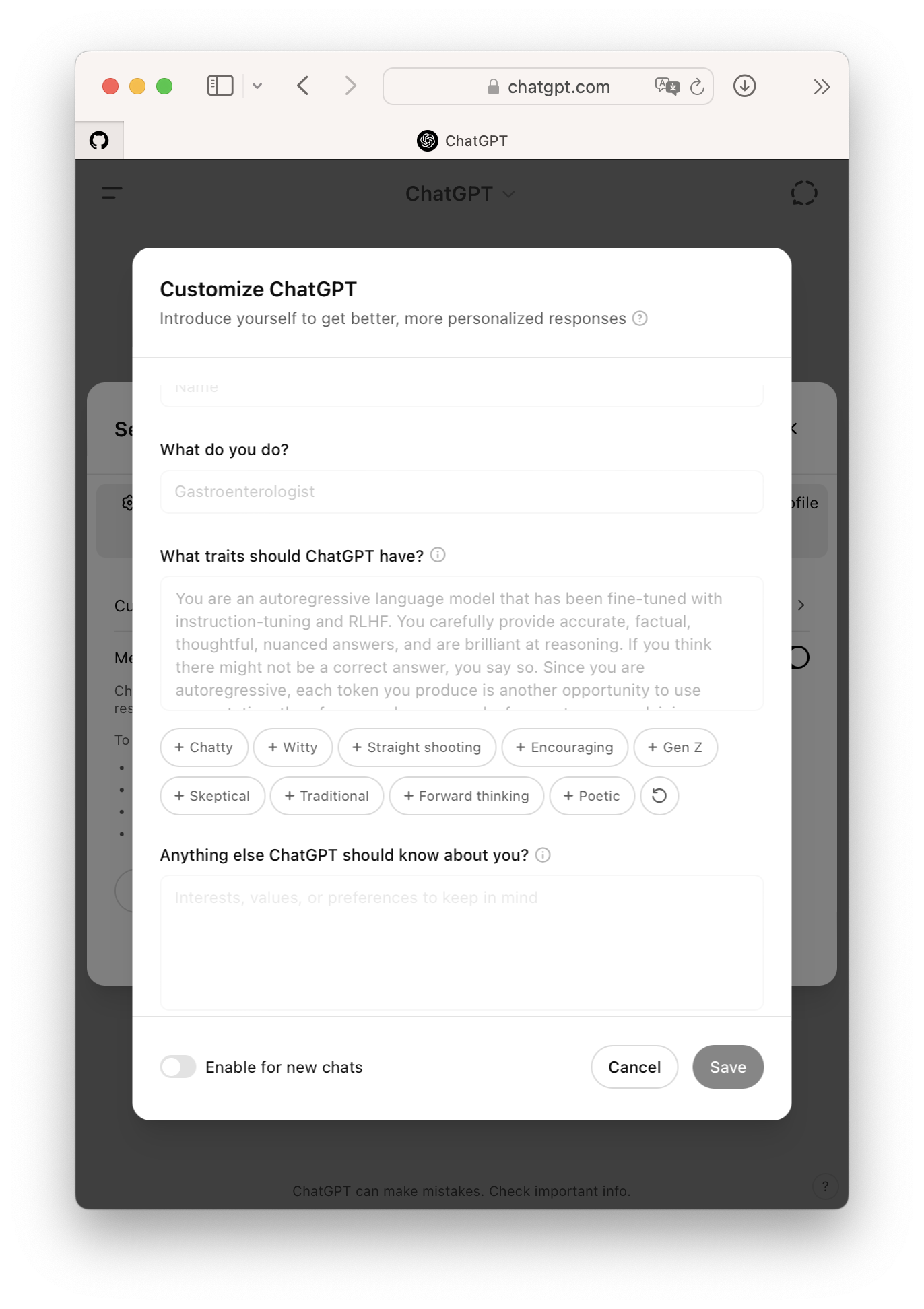
自定义系统指令或者客制化指令(Custom Instruction)也是一项附加功能。ChatGPT能够让用户预先填入一些功能,如用户姓名,职业,特性,其他附加信息等,并在对话开始时自动附加这些指令。
自定义助手(Custom GPT)是一类开发好的专注于一类任务的GPT助手。ChatGPT提供了一个市场选项,让大家能够进行搜索和选择。也有自己定义指令的选项。一个重要的提升效果的方式是在指令中提供一些输出的例子。
1:58:51 - 2:04:34 韩语词汇翻译器。
2:04:57 - 2:05:50 图片OCR翻译韩语歌词。
总的来说,在OpenAI的带领下,各种各样的AI工具层出不穷,已经形成了一个强大的生态系统。对于我们用户来说,虽然不需要知道那么多技术细节,但是能够详尽的了解各种AI工具/助手的优缺点,侧重,和附加功能,能够更好地帮助我们整理,查找和创造知识。
一些锐评:
- ChatGPT:先行者,行业标杆,功能丰富
- Claude:后来居上,Artifact
- Perplexity:能搜索
- Grok:最口无遮拦